Well-Calibrated Result Probabilities and Human Move Prediction for Elite Classical Chess
Summary
The paper describes two machine-learning models for elite classical chess: a result prediction model that outputs well-calibrated win/draw/loss probabilities for the current position, and a move prediction model that ranks legal candidate moves by how likely a strong human would play each one. Both are gradient-boosted decision-tree ensembles (LightGBM) built on features from Stockfish evaluations, an upstream human-imitation policy network, and a range of position- and game-level signals. The models are trained on ~464k classical chess games from The Week in Chess in which both players are rated 2400 Elo or higher, and evaluated on an 82k-game evaluation set held out from the training pool. On the result task the production model (which does not see the rating gap between the two players) reaches an expected calibration error of 0.002 on 6.78M held-out positions. On the move task the production model reaches 61.9% top-1 / 88.4% top-3 accuracy, versus 55.8% / 80.6% for an engine-best-move baseline evaluated on the same positions. Both models are deployed on chessds.com in two latency tiers (around 200 ms and 1 s per position on a single CPU core). To the author's knowledge, there are no published data showing better performance on these tasks for elite classical chess.
Result prediction
Normalized entropy (NE) is the slice's log loss divided by the entropy of that slice's outcome distribution: NE = 1 corresponds to a log loss equal to the slice's own prior entropy (what a predictor that exactly tracked the slice's class frequencies would achieve), and NE = 0 corresponds to a model that places all probability mass on the realized outcome on every position. Expected calibration error (ECE) bins predictions by the model's top predicted probability and reports the size-weighted average gap between predicted confidence and empirical frequency in each bin: when the model says 70%, is it right about 70% of the time?
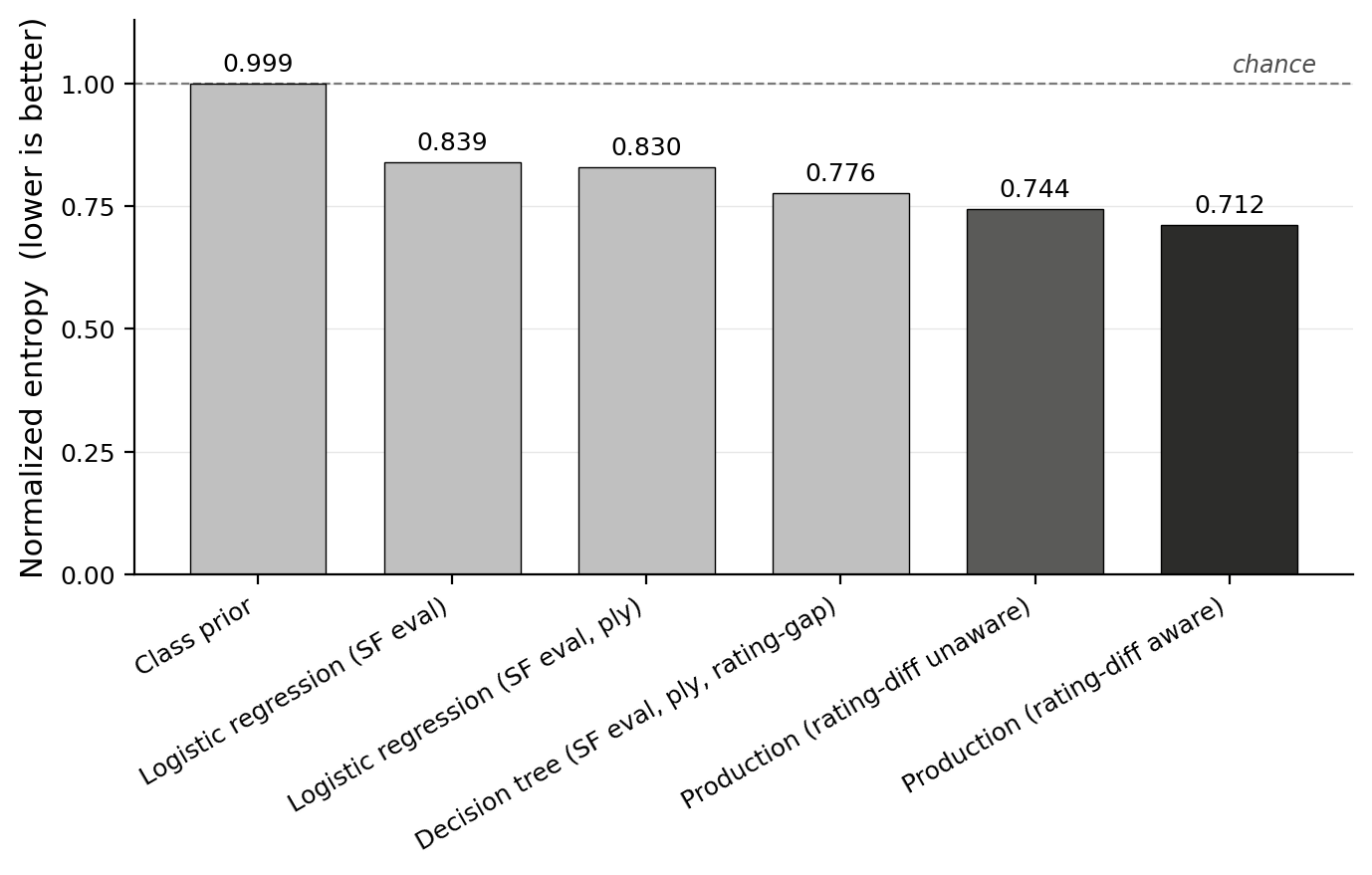
The production rating-gap-unaware model reaches NE ≈ 0.735 and ECE ≈ 0.002, and the rating-gap-aware variant reaches NE ≈ 0.702 with ECE ≈ 0.003. Calibration around 0.002–0.003 means that when the model reports a probability, that probability is, on average, within two to three tenths of a percentage point of the empirical frequency at that confidence level. This is the most user-visible property of the result model.
Move prediction
Top-1 accuracy is the fraction of positions where the played move has the highest predicted probability among the legal candidates; top-3 is the fraction where the played move is in the top three. The production move model reaches 61.89% top-1 / 88.39% top-3 / MRR 0.760 / per-position log loss 1.095 on the full 82k-game evaluation set.
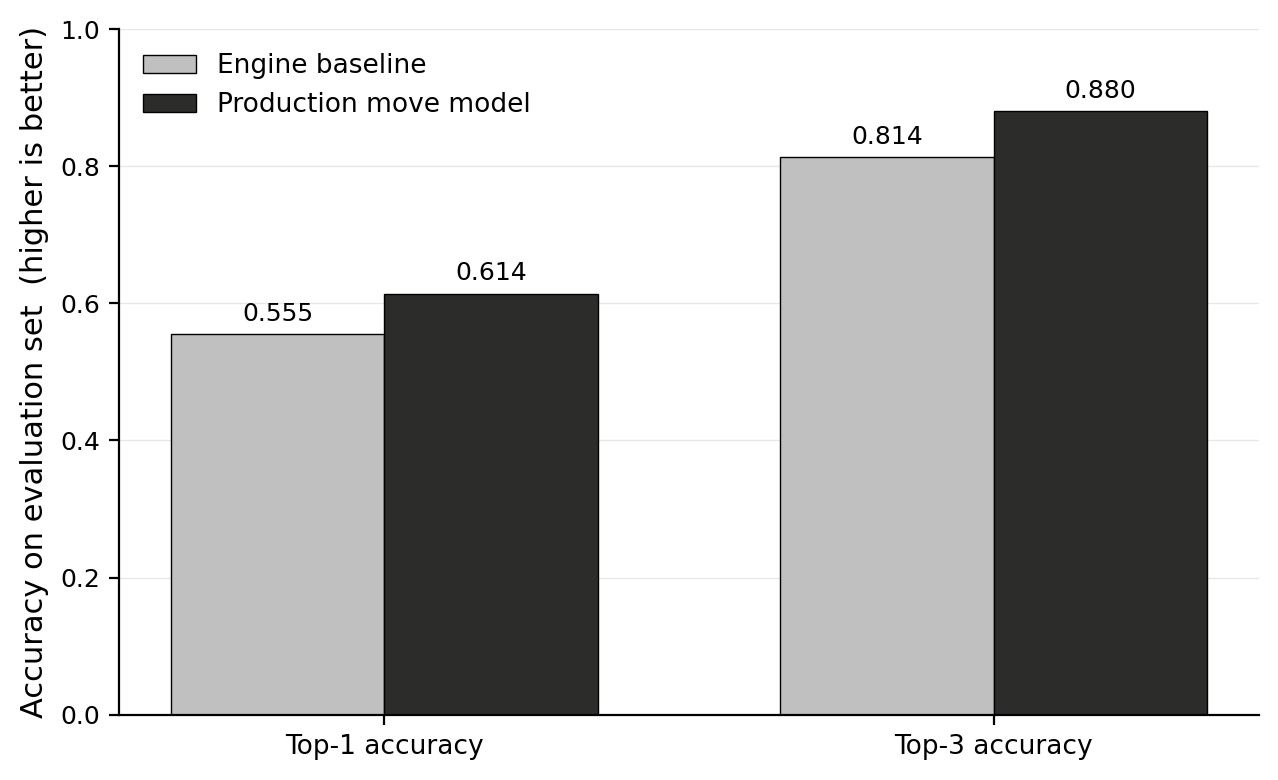
A natural baseline for this task is “just predict the engine's best move.” On the same evaluation set, this baseline reaches 55.82% top-1 / 80.61% top-3. The learned model is 6.07 pp better in top-1 overall, with the largest gap in the opening (+8.24 pp).
Scaling behavior
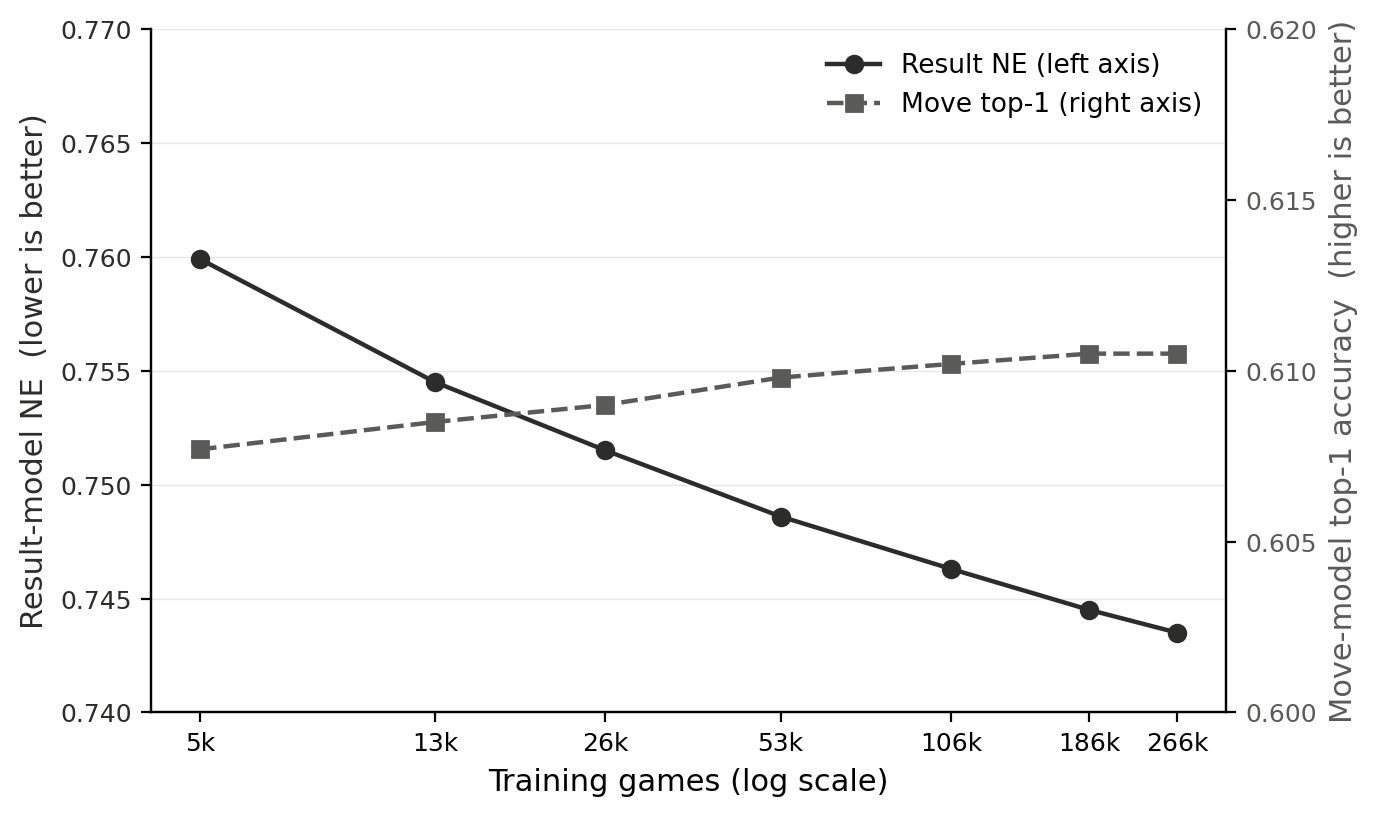
Both models were trained at nine nested training-set sizes from 5k to 464k games (each a subset of the next), with every other setting held fixed within each sweep, and evaluated on the 82k-game holdout. For the result model NE drops from 0.752 at 5k games to 0.735 at 464k games; for the move model top-1 accuracy rises from 61.44% to 61.89% over the same range. Both curves are monotonically improving (or flat) across every point. The marginal gains from additional data shrink sharply past about 100k games.
Method, in brief
Both models are LightGBM gradient-boosted decision-tree ensembles. The result model is a three-class softmax over win/draw/loss; the move model is trained with the LambdaRank objective, with each (game, ply) treated as a query group and the played move as the single relevant candidate. Inputs are position-level feature vectors: ~140 features for the result model and ~70 for the move model. The features draw on Stockfish 18 evaluations of the current position and its candidate moves, the move sequence leading to the current position, properties of the position itself, and the players' Elo ratings. A small upstream policy network (~1.2M-parameter ResNet trained on the same TWIC pool with cross-entropy on the played move) produces policy-derived features that feed the move model directly, plus a smaller set of position-level summaries that feed the result model. Inference is sequential within each game: positions are fed through the pipeline in order so that history-derived features describe the actual game history up to the current ply.
Full results — including per-slice tables, calibration analysis, comparison to prior work, and dataset/method details — are in the PDF.
How to cite
@techreport{hamood2026chessds,
author = {Hamood, Albert W.},
title = {Well-Calibrated Result Probabilities and Human Move
Prediction for Elite Classical Chess},
year = {2026},
month = {April},
institution = {Zenodo},
doi = {10.5281/zenodo.19988688},
url = {https://doi.org/10.5281/zenodo.19988688}
}